커다란 2의 제곱수는 어떤 수 보다 1자리수가 많으면서 1로 시작하고 나머지가 0인 수다. 예를 들어 011의 커다란 2의 제곱수는 1000이다.
2의 보수에서 2는 2^n 의 2다. 2의 보수는 2^n 을 만드는 수다.
예를 들어 2진수 011이 있다고 하면 011의 2의 보수는 101 이다. 2진수 011은 길이가 3이다. 길이를 2^n 의 n 에 대입하면 2^3 이고 이는 10진수로 표현하면 8이고 2진수로 표현하면 1000이다. 즉 011의 2의 보수는 1000을 만드는 수다. 011에서 101을 더하면 1000이 된다.
2진수
10진수
0000
0
0001
1
0010
2
0011
3
0100
4
0101
5
0110
6
0111
7
1111
-1
1110
-2
1101
-3
1100
-4
1011
-5
1010
-6
1001
-7
1000
-8
2의 보수는 1의 보수에서 1을 더한다. 자리수를 모두 반전하고 1을 더하면 2의 보수를 구할 수 있다. 5의 2의 보수는 아래와 같이 구할 수 있다.
0101(2) -> 5
1010(2) -> 비트를 모두 반전
1011(2) -> 1을 더한다 (2의 보수)
0이 1개
부호 절대값, 1의 보수와 달리 2의 보수는 0이 1개다.
캐리는 무시
2의 보수에서 캐리는 무시하면 되는데 오버플로우는 막을 수 없다.
오버플로우는 비트로 표현할 수 있는 수의 범위를 벗어난 경우다. 캐리는 오류가 아니지만 오버플로우는 오류다.
캐리 O, 오버플로우 X
0001
+ 1111
------
1 0000
(캐리 발생)
1 + (-1)은 0이다.
이진수 연산을 하면 캐리가 발생하는데 캐리를 제외하고 나머지 비트를 보면 0000으로 0이 나왔다. 캐리는 무시한다.
캐리 X, 오버플로우 O
0001
+ 0111
------
1000
1 + 7은 8이다.
4비트에서 2의 보수로 표현할 수 있는 수의 범위는 -8 ~ 7이다. 8은 4비트에서 표현할 수 있는 수의 범위를 벗어났다.
1000은 2의 보수에서 -8이다. 오버플로우가 발생해서 올바른 연산 결과가 나오지 않았다.
캐리 X, 오버플로우 X
0001
+ 0011
------
0100
1 + 3은 4다.
이 경우 캐리와 오버플로우 모두 발생하지 않았다. 정상적인 연산 결과가 나왔다.
캐리 O, 오버플로우 O
1110
+ 1001
------
1 0111
(캐리 발생)
-2 + (-7) 은 -9다.
이진수 연산시 7이 나온다. 오버플로우가 발생해서 올바른 연산 결과가 나오지 않았다. 캐리도 발생했으나 캐리는 무시한다.
-0b1010
접두어 0b
print(0b1001)
# 9
print(~0b1001)
# -10
# (~ 과 - 의 구분에 주의)
파이썬에서는 이진수임을 나타내기 위해 이진수 앞에 0b 접두어를 붙인다.
-0b1010은 접두어 0b 앞에 -가 붙었는데 이는 어떤 의미일까?
1010이 8비트 단위의 이진수였다면 1010은 00001010과 같다.
파이썬에서 정수 크기는 8비트 보다 훨씬 크기(파이썬의 정수 크기는 기본적으로 28바이트고 이보다 더 큰 수도 표현이 가능해서 사실상 무한대라고 볼 수 있다고 한다) 때문에 0b1010는 0b와 1010사이에 아주 많은 0이 생략되어 있다고 할 수 있다.
~(tilde)
파이썬에서 ~(tilde) 는 비트를 반전한다.
10진수 9는 2진수로 0b1001이고 0b와 1001사이에는 아주 많은 0이 생략됐다.
0b1001을 비트 반전하면 0b와 1001사이에 있던 아주 많은 0이 모두 1이 된다. 그대로 나타내려면 화면에 아주 많은 공간이 필요하다.
비트 반전은 2의 보수에서 1을 뺀 값과 같다.
비트 반전은 1의 보수를 구하는 것과 같고, 1의 보수는 2의 보수에서 1을 뺀 값이다. 반대로 2의 보수는 1의 보수에서 1을 더한 값이다. 파이썬은 음수를 나타내기 위해 2의 보수법을 사용한다.
2의 보수법에서 비트 반전
0010(2) -> 2
1101(2) -> -3
따라서 9를 비트 반전하면 -10이 된다.
-10을 2의 보수법으로 나타내려면 1을 아주 많이 표시해야 해서 화면에 많은 공간이 필요하다.
이를 간략하게 나타내기 위해 -를 사용할 수 있다.
-(minus)
이진수 0b1001(0b와 10001사이에 아주 많은 0이 생략된 상태)의 비트 반전은 0b111....0110 과 같다.
비트 반전한 수는 2의 보수법에서 -10이다. -10을 이진수로 간략하게 나타내기 위해 먼저 -와 10을 나눠서 다룬다.
10을 이진수로 표현하면 0b1010(0b 와 1010 사이에 아주 많은 0이 생략된 상태)고 이진수 앞에 -를 붙여서 표현하면 -0b1010이다.
별도로 선언하지 않으면 디폴트로 참조 테이블의 PK(Primary Key) 컬럼명이 설정된다.
예시
create table post
(
id int primary key auto_increment,
title varchar(50) not null,
content varchar(200) not null
);
create table comment
(
id int primary key auto_increment,
post_id int not null,
content varchar(200) not null,
foreign key (post_id) references post(id)
);
post, comment 테이블의 구조는 위와 같다.
@Entity
@Table(name = "post")
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(length = 50, nullable = false)
private String title;
@Column(length = 200, nullable = false)
private String content;
@OneToMany(mappedBy = "post")
private List<Comment> comments;
}
@Entity
@Table(name = "comment")
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "post_id", nullable = false)
private Post post;
@Column(length = 200, nullable = false)
private String content;
}
post, comment 테이블을 엔티티로 각각 Post, Comment 로 표현했다.
두 엔티티는 1:N 양방향 연관관계를 맺는다.
Comment 엔티티의 @JoinColumn 어노테이션의 name 속성 값으로 post_id 를 설정했다. comment 테이블에서 post 테이블의 id 컬럼을 조회할 외래키를 post_id 로 설정했다. name 속성 값은 이 post_id 를 가리킨다.
위 예시에서 Comment 엔티티의 @JoinColumn 어노테이션에 referencedColumnName 을 작성하지 않았지만 만약에 작성한다면 id 로 작성하면 된다. post 테이블의 pk 컬럼명이 id 다.
IP 주소에서 IP 는 Internet Protocol 을 나타낸다. Internet Protocol 은 네트워크간에 이동하는 패킷 단위로 나눈 네트워크 데이터를 정확한 목적지로 보내기 위한 규약이다.
IP 주소는 Internet 에 연결된 모든 기기가 갖는 고유한 식별자다. IP 주소는 네트워크 ID (Network ID) 와 호스트 ID (Host ID) 로 구성된다. 네트워크 ID 가 네트워크 대역이라면 호스트 ID 는 같은 네트워크 대역을 공유하는 기기 하나라고 볼 수 있다.
IP 클래스와 CIDR
IP 주소는 IPv4, IPv6 2가지 종류가 있다. IP 클래스는 IPv4 주소에서 존재하는 방식이고 1993년부터는 CIDR 로 대체됐다.
IPv4 주소는 32비트의 이진수로 구성되어 있고 32비트를 8비트씩 4개로 나눠서 나타낸다. 각 8비트를 옥탯(Octet) 이라고 부른다.
IP 클래스는 5개 종류가 있고 클래스마다 네트워크 ID 와 호스트 ID 의 크기가 다르다. 각 IP 클래스는 고정된 네트워크, 호스트 크기를 갖는다.
네트워크
호스트
첫번째 옥텟의 고정 비트
IP 범위
클래스 A
8비트
24비트
0
0.0.0.0 ~ 127.255.255.255
클래스 B
16비트
16비트
10
128.0.0.0 ~ 191.255.255.255
클래스 C
24비트
8비트
110
192.0.0.0 ~ 223.255.255.255
클래스 D
1110
224.0.0.0 ~ 239.255.255.255
클래스 E
1111
240.0.0.0 ~ 255.255.255.255
클래스 D 멀티캐스팅용, 클래스 E는 예약주소라 일반적으로 사용되지 않는다고 한다. AWS, Cloudflare 문서에서는 클래스 D, E 를 제외하고 클래스 A, B, C 만 다룬다.
클래스 A 에서는 하나의 네트워크가 2 ^ 24개의 호스트, 클래스 B는 하나의 네트워크가 2 ^ 16 개의 호스트, 클래스 C 는 하나의 네트워크가 2 ^ 8개의 호스트를 갖는다.
CIDR
하나의 IP 를 할당받은 사용자는 호스트가 100가 필요한데 할당받은 IP 는 호스트 200개까지 가질 수 있다고 하면 100개가 낭비된다. IP 클래스는 고정된 네트워크, 호스트 크기를 갖기 때문에 호스트 크기를 유연하게 조절하기 어렵다. 이를 개선하기 위해 CIDR 이 나오게 된다. CIDR 은 1993년부터 IP 클래스를 대체해서 사용되고 있다.
CIDR 은 IP 주소에 접두어 길이를 함께 표기한다. 접두어 길이는 네트워크 ID 의 비트 수를 의미한다.
// IP 주소
255.255.255.128 /25
위와 같은 IP 주소는 네트워크 ID 가 25비트고 호스트 ID 가 7비트로 이루어진다. IP 클래스와 달리 네트워크 ID 를 8, 16, 24 비트 외에 세분화해서 나눌 수 있다.
트랜잭션 격리 수준은 서로 다른 트랜잭션이 같은 데이터에 접근할때 데이터를 처리하는 방법과 관련이 있다.
격리 수준은 READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE 4가지로 나눌 수 있다.
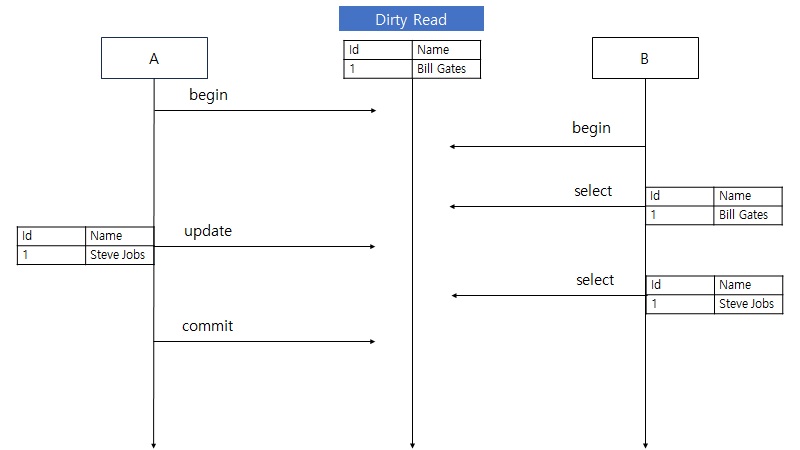
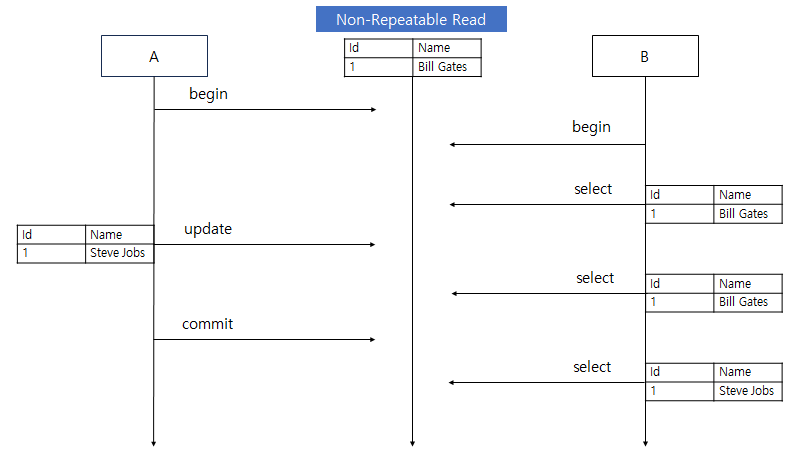
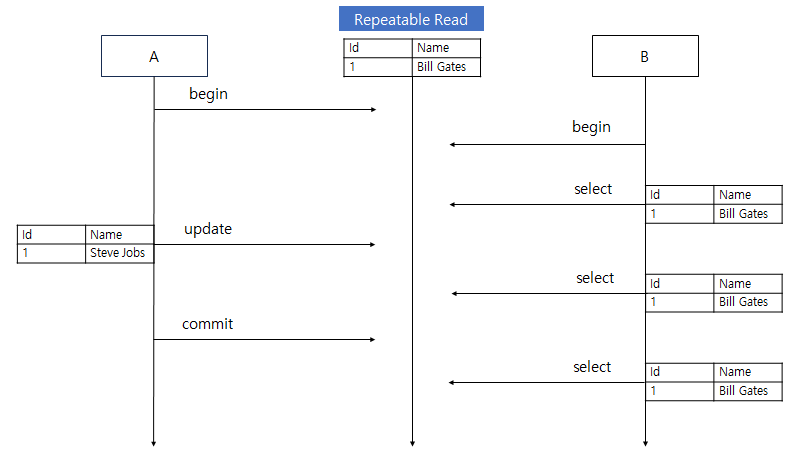
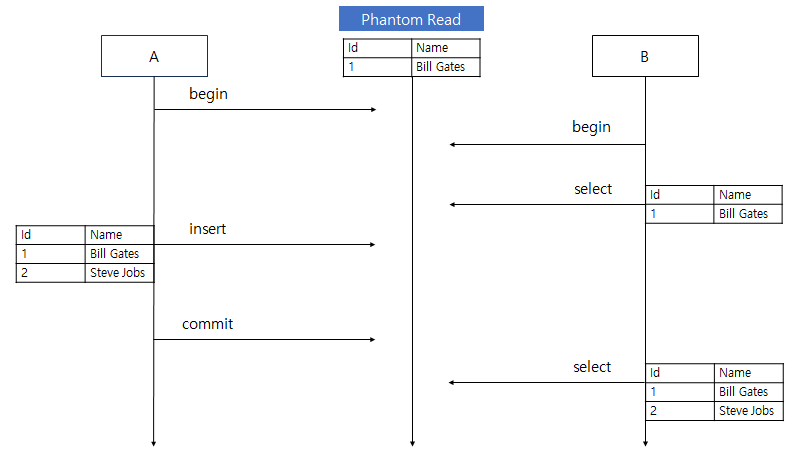
격리 수준에 따라 발생할 수 있는 문제가 달라지는데, 이 문제는 Dirty Read, Non Repetable Read, Phantom Read 3가지가 있다.
Dirty Read
Non Repetable Read
Phantom Read
READ UNCOMMITTED
O
O
O
READ COMMITTED
X
O
O
REPETABLE READ
X
X
O (MySQL InnoDB, PostgreSQL 는 X)
SERIALIZABLE
X
X
X
격리 수준
글에서 언급할 트랜잭션 A, 트랜잭션 B 는 트랜잭션을 구분하기 위해 임의로 정한 트랜잭션 이름이다.
READ UNCOMMITTED
트랜잭션 A 에서 변경한 내용을 commit 여부와 관계없이 트랜잭션 B 에서도 볼 수 있는 격리 수준이다. 이 현상을 Dirty Read 라고 한다.
Dirty Read 뿐만 아니라 Non Repeatable Read 와 Phantom Read 도 발생한다.
READ COMMITTED
트랜잭션 A 에서 commit 한 데이터만 트랜잭션 B 에서 볼 수 있으나 트랜잭션 B 에서 동일한 데이터를 조회할 때 결과가 서로 다른 Non Repeatable Read 문제가 발생할 수 있다. Non Repeatable Read 는 Update 쿼리와 연관해서 생각해볼 수 있다.
트랜잭션 A 가 시작하고 한 데이터를 update 했으나 commit 을 아직 하지 않은 상태에서 트랜잭션 B 가 동일한 데이터를 조회하면 A 가 update 하기 전의 결과가 조회된다. 그러나 A 가 commit 을 하고나서 B 의 트랜잭션이 끝나기 전에 다시 B 가 동일한 데이터를 조회하면 A 가 update 한 결과가 조회된다.
한 트랜잭션 안에서 동일한 데이터를 조회할 때 서로 다른 결과가 나올 수 있다.
Dirty Read 는 발생하지 않으나 Non Repeatable Read 뿐만 아니라 Phantom Read 도 발생한다.
REPEATABLE READ
앞에서 언급한 Dirty Read, Non Repeatable Read 문제는 발생하지 않으나 REPEATABLE READ 격리 수준에서는 Phantom Read 문제가 발생할 수 있다.
단, MySQL 의 InnoDB 와 PostgreSQL 에서는 REPEATABLE READ 격리 수준에서 Phantom Read 문제가 발생하지 않는다. MySQL InnoDB 은 디폴트 격리 수준으로 REPETABLE READ 를 사용한다.
Phantom Read 는 이름에서 느껴지듯 다른 트랜잭션의 변경에 의해 트랜잭션 내에서 데이터가 마치 유령처럼 생겼다 없어졌다 하는 현상이 발생한다. Phantom Read 는 Insert 쿼리와 연관지어 생각해볼 수 있다.
트랜잭션 A 에서 Insert 쿼리로 테이블에 (Idx: 2, Name: Steve Jobs) row 를 추가한다고 할때 insert 쿼리가 발생하기 전에 트랜잭션 B 에서 트랜잭션을 시작하고 이 테이블의 모든 row 를 조회했을 때는 (Idx: 2, Name: Steve Jobs) 가 보이지 않는다.
그러나 A 의 insert 가 발생하고 commit 까지 끝나고 나서 B 의 트랜잭션이 끝나기 전에 다시 이 테이블의 모든 row 를 조회했을 때 이전에 없었던 (Idx: 2, Name: Steve Jobs) 가 보이게 되는 현상이 Phantom Read 다.
SERIALIZABLE
가장 엄격한 격리 수준으로 Dirty Read, Non Repeatable Read, Phantom Read 문제가 발생하지 않는다. 그만큼 동시 처리 성능은 떨어지지만 데이터 정합성이 높다.
NestJS 에서 의존성 주입은 IoC Container 에 의해서 수행될 수 있다. 개발자는 직접 의존성을 주입하거나, 인스턴스를 생성하거나, 혹은 초기화할 필요가 없다.
NestJS 의 Provider 또한 IoC Container 의 의존성 주입으로 사용할 수 있다. 의존성 주입을 하는 Provider 의 타입을 이 Provider 가 상속 받은 추상 클래스로 선언하고 싶었다.
의존성 주입을 통해 의존할 대상을 내부에서 직접 생성하는게 아니라 외부로부터 전달 받을 수 있다. 내부에서 직접 의존할 대상을 생성하지 않게 되면서 런타임에 다양한 인스턴스를 외부에서 주입 받을 수 있다.
예를 들어 아래와 같은 추상 클래스 Car 를 상속받은 Mercedes, BMW 클래스가 있다고 가정한다.
abstract class Car {
abstract drive(): void;
}
class Mercedes extends Car {
@override
drive() {
console.log('mercedes');
}
}
class BMW extends Car {
@override
drive() {
console.log('bmw');
}
}
Driver 클래스에서 Car 를 주입 받는다. 여기서 car 의 타입을 Mercedes 나 BMW 가 아닌 Car 로 선언했다.
Driver 의 인스턴스를 생성할때 Mercedes, BMW 중 원하는 클래스를 주입한다. 만약에 Driver 의 car 변수의 타입을 Mercedes, BMW 둘 중 하나로 선언하면 선언한 타입에 따라 Mercedes, BMW 둘 중 하나만 주입할 수 있다.
const driver1: Driver = new Driver(new Mercedes());
driver1.operate();
// 'mercedes'
const driver2: Driver = new Driver(new BMW());
driver2.operate();
// 'bmw'
2. Abstract Class Injection (추상 클래스 주입)
이를 응용해서 NestJS 에서도 추상 클래스 타입으로 의존성을 주입받고 싶었으나 원하는대로 되지 않았다.
비슷한 기능을 하는 여러 클래스들을 추상 클래스로 묶고 싶었다. 예를 들어 포인트를 적립하는 기능을 개발하는데 포인트 종류가 여러개면 포인트 종류별로 클래스를 만들 수 있다.
포인트 클래스의 기능은 공통적으로 적립 기능인데 클래스마다 구현이 달라진다. 포인트 종류가 추가될 때마다 클래스도 추가 되어야 하는데 만약 메소드명이 클래스마다 다르다면 같은 기능이더라도 각 클래스마다 호출할 때 메소드명이 무엇인지 파악해야 한다. 이러한 불편함을 해결하기 위해 상위 클래스로 추상 클래스를 사용할 수 있다.
export abstract class Point {
abstract savePoint(): void;
}
포인트 종류가 추가되어 새 클래스를 구현할때 이제 Point 를 상속 받아서 추상 메소드인 savePoint 를 구현하도록 할 수 있고 메소드를 호출할 때도 동일한 메소드명이 호출되어서 코드를 파악하기도 편해졌다.
@Injectable
export class APointService extends Point {
savePoint() {
console.log('a-point');
}
}
@Injectable
export class BPointService extends Point {
savePoint() {
console.log('b-point');
}
}
PointModule 에서는 PointFactoryModule 을 import 해온다. 그리고 PointController, PointService 를 각각 controller 와 provider 로 등록한다.
PointService 에서는 PointFactoryService 를 주입 받아 사용한다. savePoint 메소드에서 getPointService 메소드를 통해 APointService 혹은 BPointService 를 리턴받아 해당 클래스에 정의한 savePoint 메소드를 호출하게 된다.
편의상 여기서는 getPointService 의 인자를 직접 PointType.A 로 넣어줬다.
팩토리 패턴 을 통해 PointFactoryService 에서 Point 클래스를 상속받은 서비스를 찾아준다. APointService, BPointService 를 PointFactoryService 의 providers 프로퍼티에 등록한다. Nest IoC Container 에 의해 PointFactoryService 는 APointService, BPointService 를 주입 받아 사용할 수 있다.
APointService, BPointService 를 Custom Provider 로 등록한다. NestJS 에서 내부적으로 Custom Provider 여부를 어떻게 판단하는지는 마지막에 다룰 예정이다.
@Module({
providers: [
PointFactoryService,
{
provide: Point,
useClass: APointService,
},
{
provide: Point,
useClass: BPointService,
}
],
exports: [PointFactoryService],
})
export class PointFactoryModule {}
PointFactoryService 에서는 주입받은 APointService, BPointService 를 pointMap 으로 선언한 Map 에 등록한다. getPointService 메소드에서 PointType 에 해당하는 key 로 pointMap 를 조회해서 value 로 등록한 서비스를 리턴한다.
@Injectable()
export class PointFactoryService {
private pointMap = new Map<PointType, Point>();
constructor(
private readonly aPointService: Point,
private readonly bPointService: Point,
) {
this.pointMap.set(PointType.A, this.aPointService);
this.pointMap.set(PointType.B, this.bPointService);
}
getPointService(pointType: PointType) {
return this.pointMap.get(pointType);
}
}
export enum PointType {
A = 'a',
B = 'b',
}
3. 문제 상황
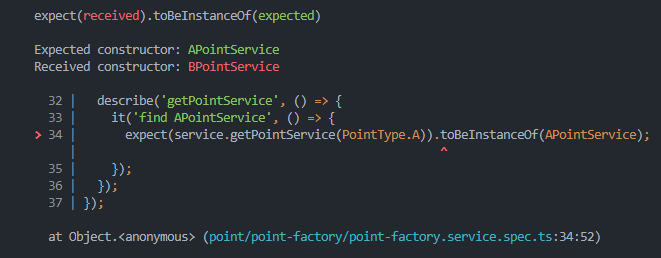
위에서 언급한 PointService 코드를 다시 살펴보겠다. savePoint 메소드를 호출했을때 기대한 결과는 'a-point' 인데 실제로는 'b-point' 가 나온다.
다음은 DependenciesScanner 클래스의 일부 코드다. 모듈들을 스캔한 후에 스캔한 모듈들의 의존성을 스캔한다. 여기서 모듈은 AppModule 과 AppModule 의imports 에 선언한 Module 들을 가리킨다.
모듈 스캔은 AppModule 을 중심으로 재귀적으로 AppModule 에 선언한 Module 들을 스캔한다. 그리고 이 모듈들의 의존성 스캔은 controllers, providers 등으로 선언한 의존성을 스캔한다. 이 글에서는 providers 를 중심으로 살펴볼 예정이다.
// core/scanner.ts
export class DependenciesScanner {
public async scan(module: Type<any>) {
await this.registerCoreModule();
await this.scanForModules(module); // 모듈들 스캔
await this.scanModulesForDependencies(); // (1) scanForModules 로 스캔한 모듈들의 의존성 스캔
this.calculateModulesDistance();
this.addScopedEnhancersMetadata();
this.container.bindGlobalScope();
}
public async scanModulesForDependencies(
modules: Map<string, Module> = this.container.getModules(),
) {
// modules -> ModulesContainer
// ModulesContainer 는 Map<String, Module> 을 상속받은 클래스로
// 키가 string, 값이 Module 이다
//
// modules 에서 for loop 돌면서 token, { metatype } 꺼낸다
// key 가 token 이고, value 는 Module 클래스인데 Module 의 metatype 속성을 구조 분해 할당으로 꺼낸다
for (const [token, { metatype }] of modules) {
await this.reflectImports(metatype, token, metatype.name);
this.reflectProviders(metatype, token); // (2) 모듈의 provider 스캔
this.reflectControllers(metatype, token);
this.reflectExports(metatype, token);
}
}
public reflectProviders(module: Type<any>, token: string) {
const providers = [
// reflectMetadata 메소드는
// MODULE_METADATA.PROVIDERS 를 key, module 을 target 으로
// Reflect 모듈의 getMetadata 메소드를 호출한다
// providers 를 키로 사전에 메타데이터 등록을 해놓은 provider 중에
// module 에 해당하는 객체를 찾는다
...this.reflectMetadata(MODULE_METADATA.PROVIDERS, module),
...this.container.getDynamicMetadataByToken(
token,
MODULE_METADATA.PROVIDERS as 'providers',
),
];
// 위에서 찾은 providers 를 forEach 문을 돌면서
// insertProvider 메소드를 통해
// NestContainer 의 변수인 modules (ModulesContainer 인스턴스) 로부터 Module 을 조회하여
// 해당 Module 에 provider 를 등록한다
providers.forEach(provider => {
this.insertProvider(provider, token); // (3)
this.reflectDynamicMetadata(provider, token);
});
}
public insertProvider(provider: Provider, token: string) {
const isCustomProvider = this.isCustomProvider(provider);
if (!isCustomProvider) {
// custom provider 가 아니면 provider 를 바로 Module 에 등록한다
return this.container.addProvider(provider as Type<any>, token);
}
// Global 로 선언한 Interceptor, Pipe, Guard, Filter 등을 담은 객체
const applyProvidersMap = this.getApplyProvidersMap();
const providersKeys = Object.keys(applyProvidersMap);
// 해당 Provider 가 provide 키로 등록한 값을 조회하여 type 변수에 대입한다
// ex> { provide: AService, useClass: AService }
// 위의 경우 AService 가 type 변수에 담긴다
const type = (
provider as
| ClassProvider
| ValueProvider
| FactoryProvider
| ExistingProvider
).provide;
// Provider 가 Global 로 선언한 Interceptor, Pipe, Guard, Filter 에 해당하지 않는다면
// addProvider 메소드를 호출한다
// 위에서 생성한 APointService, BPointService 등은 이 if 문을 충족해서
// addProvider 메소드를 호출한다
if (!providersKeys.includes(type as string)) {
return this.container.addProvider(provider as any, token);
}
// UuidFactory의 mode 는 random, deterministic 두가지가 있는데
// 이는 NestFactoryStatic 의 create 함수를 호출하는 방식에 의해 결정된다
// NestFactoryStatic 의 create 함수는 NestJS 의 진입점인
// main.ts 의 bootstrap 함수에서 호출된다
// 디폴트로는 create 에 AppModule 만 인자로 넣어서 호출하는데
// 선택적으로 두번째 인자로 NestApplicationOptions 를 넣어줄 수 있다
// 이를 따로 넣지 않는한 random mode 가 된다
// random mode 는 randomStringGenerator 함수를 통해 (uid 모듈을 사용하여)
// 21자리 랜덤한 문자열을 생성한다
// 이렇게 생성한 랜덤 문자열을 uuid 변수에 담는다
// (UuidFactory.get 에서 type.toString() 인자를 넣는데 random mode 에서는 이 인자를 사용하지 않고 인자와 관계없이 랜덤 문자열을 생성한다)
const uuid = UuidFactory.get(type.toString());
// type 과 uuid 를 결합해 providerToken 을 생성한다
const providerToken = `${type as string} (UUID: ${uuid})`;
let scope = (provider as ClassProvider | FactoryProvider).scope;
if (isNil(scope) && (provider as ClassProvider).useClass) {
scope = getClassScope((provider as ClassProvider).useClass);
}
this.applicationProvidersApplyMap.push({
type,
moduleKey: token,
providerKey: providerToken,
scope,
});
const newProvider = {
...provider,
provide: providerToken,
scope,
} as Provider;
const enhancerSubtype =
ENHANCER_TOKEN_TO_SUBTYPE_MAP[
type as
| typeof APP_GUARD
| typeof APP_PIPE
| typeof APP_FILTER
| typeof APP_INTERCEPTOR
];
const factoryOrClassProvider = newProvider as
| FactoryProvider
| ClassProvider;
// Scope 의 종류로 DEFAULT, TRANSIENT, REQUEST 가 있는데
// 디폴트는 DEFAULT 다
// 그래서 이 함수의 조건은 충족하지 않는다
if (this.isRequestOrTransient(factoryOrClassProvider.scope)) {
return this.container.addInjectable(newProvider, token, enhancerSubtype);
}
this.container.addProvider(newProvider, token, enhancerSubtype);
}
}
4-2. 스캔한 의존성 등록
스캔한 의존성들을 등록한다.
// core/injector/container.ts
export class NestContainer {
private readonly modules = new ModulesContainer();
public getModules(): ModulesContainer {
return this.modules;
}
public addProvider(
provider: Provider,
token: string,
enhancerSubtype?: EnhancerSubtype,
): string | symbol | Function {
// ModulesContainer 클래스에서 token 으로 module 을 조회한다
// ModulesContainer 클래스는 Map<string, Module> 을 상속 받은 클래스다
// 키가 token, 값이 Module 이다
// token 은 위의 DependenciesScanner 에서 살펴본 providerToken 이다
const moduleRef = this.modules.get(token);
if (!provider) {
throw new CircularDependencyException(moduleRef?.metatype.name);
}
if (!moduleRef) {
throw new UnknownModuleException();
}
return moduleRef.addProvider(provider, enhancerSubtype) as Function;
}
}
Module 클래스의 addCustomClass 메소드가 추상 클래스 주입시 발생한 문제의 핵심이다. @Module 의 providers 에 등록할때 provide, useClass 를 사용했었는데 이때 provide 를 키로 사용해서 Map 에 등록하게 된다. 결국 Map 에는 키가 중복되지 않아서 동일한 키로 여러개의 값을 등록할 경우 마지막에 등록한 값으로 덮인다.
export class Module {
// Module 들을 ModulesContainer 에서 Map 으로 관리하듯이
// 각 Module 도 Map 으로 자신의 provider 들을 _providers 변수로 관리한다
// ModulesContainer -> Module 들 관리
// Module -> Provider 를 포함한 자신의 의존성 관리
private readonly _providers = new Map<
InstanceToken,
InstanceWrapper<Injectable>
>();
get providers(): Map<InstanceToken, InstanceWrapper<Injectable>> {
return this._providers;
}
public addProvider(provider: Provider, enhancerSubtype?: EnhancerSubtype) {
// CustomProvider 일 경우
if (this.isCustomProvider(provider)) {
if (this.isEntryProvider(provider.provide)) {
this._entryProviderKeys.add(provider.provide);
}
return this.addCustomProvider(provider, this._providers, enhancerSubtype);
}
this._providers.set(
// 키
provider,
// 값
new InstanceWrapper({
token: provider,
name: (provider as Type<Injectable>).name,
metatype: provider as Type<Injectable>,
instance: null,
isResolved: false,
scope: getClassScope(provider),
durable: isDurable(provider),
host: this,
}),
);
if (this.isEntryProvider(provider)) {
this._entryProviderKeys.add(provider);
}
return provider as Type<Injectable>;
}
// CustomProvider 등록
public addCustomProvider(
provider:
| ClassProvider
| FactoryProvider
| ValueProvider
| ExistingProvider,
collection: Map<Function | string | symbol, any>,
enhancerSubtype?: EnhancerSubtype,
) {
// useClass 속성으로 등록했다면 CustomClass 에 해당한다
// CustomClass 일 경우
if (this.isCustomClass(provider)) {
this.addCustomClass(provider, collection, enhancerSubtype);
} else if (this.isCustomValue(provider)) {
this.addCustomValue(provider, collection, enhancerSubtype);
} else if (this.isCustomFactory(provider)) {
this.addCustomFactory(provider, collection, enhancerSubtype);
} else if (this.isCustomUseExisting(provider)) {
this.addCustomUseExisting(provider, collection, enhancerSubtype);
}
return provider.provide;
}
// CustomClass 등록
public addCustomClass(
provider: ClassProvider,
collection: Map<InstanceToken, InstanceWrapper>,
enhancerSubtype?: EnhancerSubtype,
) {
let { scope, durable } = provider;
const { useClass } = provider;
if (isUndefined(scope)) {
scope = getClassScope(useClass);
}
if (isUndefined(durable)) {
durable = isDurable(useClass);
}
// provider 의 provide 키의 값을 token 으로 선언
const token = provider.provide;
// token 을 collection 의 키로 설정한다
// 즉 provide 에 입력한 값이 키가 되는 것이다
// 이 collection 은 Module 클래스에 private 으로 선언된
// _providers 를 가리킨다
collection.set(
token,
new InstanceWrapper({
token,
name: useClass?.name || useClass,
metatype: useClass,
instance: null,
isResolved: false,
scope,
durable,
host: this,
subtype: enhancerSubtype,
}),
);
}
}
5. 결론
NestJS 는 내부적으로 각 Module 의 providers 를 Map 형태로 관리한다.
@Module 의 providers 에 서비스들을 등록할때 provide 키를 이용해서 등록할 경우 provide 에 선언한 값을 Map 의 키로 사용한다. 그래서 provide 에 동일하게 선언한 값이 여러개일 경우 마지막에 선언한 값으로 Map 에 덮여 쓰인다.
위의 경우 APointService, BPointService 가 모두 provide 로 Point 를 사용했는데 APointService 이후에 작성한 BPointService 로 덮인다. 그래서 PointFactoryModule 의 providers 에서 Point 키로 등록된 값은 BPointService 가 된다.
@Module({
providers: [
PointFactoryService,
{
provide: Point,
useClass: APointService,
},
{
provide: Point,
useClass: BPointService,
}
],
exports: [PointFactoryService],
})
export class PointFactoryModule {}
PointFactoryService 에서는 APointService 와 BPointService 모두 사용하고 싶어도 BPointService 만 주입받게 된다. APointService 의 메소드를 호출할 수 없고 BPointService 의 메소드가 호출된다. 위의 경우 aPointService, bPointService 변수를 선언했지만 BPointService 2개가 변수명만 다르게 주입된 상황이다.
@Injectable()
export class PointFactoryService {
constructor(
private readonly aPointService: Point,
private readonly bPointService: Point,
) {}
}
클러스터 인덱스와 비클러스터 인덱스에 대해서 정리를 해보려고 한다. MySQL, SQL Server 관련 자료를 중심으로 작성했다.
Page
클러스터형, 비클러스터형 인덱스는 B-tree 자료구조를 바탕으로 저장된다. B-tree 자료구조의 각 노드들은 페이지 단위로 관리된다. 페이지는 MySQL 의 경우 16KB 가 디폴트 크기다. MySQL 5.6 버전 이상부터는 페이지 크기를 innodb_page_size 변수 설정으로 변경할 수 있다.
page 는 SQL Server 에서 데이터 저장의 가장 기본 단위다. MySQL 에서는 InnoDB 엔진이 디스크와 메모리 간의 데이터를 전달할 수 있는 최소 단위다.
디스크 저장공간은 file 에 할당되는데 file 은 논리적으로 page 단위로 구분된다.
예시 테이블 정보
아래 이미지로 나타낼 데이터들의 가상 테이블 정보는 다음과 같다.
테이블명은 Company 이며 컬럼은 name 과 founder 로 구성된다. 10개의 데이터가 들어있다.
클러스터형 인덱스란?
데이터가 저장된 페이지 자체를 정렬하는 기준이 되는 인덱스다. 테이블 당 하나만 설정할 수 있다.
PRIMARY KEY 를 지정하면 MySQL (의 InnoDB 엔진)이나 SQL Server 는 자동으로 해당 키를 클러스터형 인덱스로 지정한다.
테이블에 PRIMARY KEY 가 없으면 UNIQUE 제약 조건(MySQL 은 모든 컬럼들 중 NOT NULL 로 정의된 첫번째 UNIQUE 컬럼) 이 지정된 컬럼을 클러스터형 인덱스로 설정한다.
만약에 PRIMARY KEY, UNIQUE 제약 조건 모두 없다면 MySQL 은 GEN_CLUST_INDEX 라는 row ID 값을 갖는 가상의 6 바이트 크기의 컬럼을 생성하여 클러스터형 인덱스로 설정한다. row ID 는 데이터 행이 insert 된 순서대로 증가한다.
위는 Company 테이블의 PRIMARY KEY 로 name 컬럼이 지정된 경우다.
클러스터형 인덱스는 B-tree 의 루트 페이지와 리프 페이지를 중심으로 살펴볼 수 있다. PRIMARY KEY 를 기준으로 물리적으로 데이터가 저장된 데이터 페이지 자체를 정렬한다.
루트 페이지에는 리프 페이지의 번호와 각 리프 페이지의 첫번째 데이터 정보를 갖는다. 리프 페이지는 실제로 데이터가 저장되어 있는 데이터 페이지와 같다.
비클러스터형 인덱스
위는 Company 테이블의 인덱스로 founder 가 지정된 경우다. PRIMARY KEY 는 없다.
비클러스터형 인덱스 SECONDARY INDEX(보조 인덱스) 라고도 하며 클러스터형 인덱스와 달리 물리적으로 저장된 데이터를 정렬하지 않는다.
비클러스터형 인덱스의 리프 페이지는 데이터 페이지와 다르다. 클러스터형 인덱스와 달리 데이터 페이지 자체도 정렬되어 있지 않은 힙 형태로 구성된다.
비클러스터형 인덱스는 한 테이블에 인덱스를 여러개 설정할 수 있고, 설정한 인덱스를 기준으로 정렬한 인덱스 정보를 갖는다.
루트 페이지는 리프 페이지의 페이지 번호와 각 페이지의 첫번째 데이터 정보를 갖는다. 리프 페이지는 인덱스로 설정한 키와 해당 키를 포함한 데이터가 저장된 데이터 페이지의 위치 정보를 갖는다. 이 위치 정보는 RID 라고 하며 파일(file) 번호, 데이터 페이지(page) 번호, 행(row) 번호로 구성된다.
클러스터형 인덱스 + 비클러스터형 인덱스
위는 Company 테이블의 name 컬럼이 PRIMARY KEY 로 지정 되었고, founder 컬럼이 SECONDARY INDEX 로 지정된 경우다.
클러스터형 인덱스와 비클러스터형 인덱스가 함꼐 구성된 경우는 클러스터형 인덱스로 사용되는 PRIMARY KEY 와 함께 별도로 비클러스터형 인덱스를 보조 인덱스로 설정한 경우다.
MySQL 에서 모든 비클러스터형 인덱스는 클러스터형 인덱스의 정보를 갖는다. 그래서 클러스터형 인덱스의 크기가 커지면 비클러스터형 인덱스의 크기도 커지게 된다.
테이블에 비클러스터형 인덱스만 있을 경우에는 비클러스터형 인덱스의 리프 페이지는 RID 정보를 갖고 있고 이 RID 를 기준으로 데이터 페이지를 조회한다. 테이블에 비클러스터형 인덱스 뿐만 아니라 클러스터형 인덱스도 있을 경우에는 비클러스터형 인덱스는 클러스터형 인덱스 (컬럼) 값을 갖고 있고 클러스터형 인덱스를 기준으로 데이터 페이지에 접근한다.
baseline compiler 에 대응되는 v8 의 baseline compiler 는 Ignition 이 담당한다.
optimizing compiler 에 대응되는 v8 의 optimizing compiler 는 TurboFan 이 담당한다.
Ignition 은 baseline compiler 와 달리 machine code 가 아닌 bytecode 로 변환한다.
machine code 는 CPU 에 의해 직접 동작하는 코드라면 byte code 는 JVM 과 같은 가상 머신에서 동작하는 코드다. 가상 머신에서 동작하므로 OS 의 종류에 관계없이 동작할 수 있다.
byte code 는 machine code 와 source code 중간에 놓인 코드다. CPU 는 byte code 를 이해할 수 없어서 machine code 로 변환하는 작업이 필요하다.
machine code 와 byte code 에 대한 차이는 추가 학습이 필요하다.
re-compile & de-compile
modern JavaScript engine 은 compiler 를 대체로 2개 이상 갖는데, 그 중 하나가 Optimizing compiler 다.
Optimizing compiler 는 hot function 을 recompiling 한다. hot function 은 많이, 자주 사용되는 함수라는 의미를 갖는다.
hot function 은 많이 사용되기 때문에 최적화(optimize) 할 필요가 있다. 이때의 최적화는 machine code 에 대한 최적화를 의미한다.
Optimizing compiler 는 많이 사용되는 함수들에 대해서 정보를 수집하는데 특히 타입에 대한 정보가 중요하다. 최적화를 진행할때 이전에 사용됐던 타입과 유사한 타입을 사용할 것이라고 예상한다.
그러나 JavaScript 는 dynamically typed 하기 때문에 다른 타입을 사용할 수 있다. 그러면 Optimizing compiler 는 optimzed code 에 대한 de-optimize 를 수행하게 된다. 최적화 시켜놓은 코드를 다시 최적화하지 않은 상태로 되돌린다.
가능한 type 을 변경하지 말 것
optimizing compiler 는 이전에 사용한 type 정보를 바탕으로 최적화를 진행하므로 발표자는 이미 작성한 코드의 type 을 바꾸지 말라고 조언한다. 타입을 바꾸면 de-optimizing 을 진행하게 된다.
function load(obj) {
return obj.x;
}
load 함수는 파라미터로 선언한 obj 의 프로퍼티 x 를 반환하는 단순한 함수다.
그렇지만 compiler 에게는 꽤 복잡한 일이다. compiler 는 obj 가 x 를 실제로 갖고 있는지, 프로토타입 체인 어딘가에 속해있는지, 메모리 어디에 x 가 저장되어 있는지 등을 파악해야 한다.